使用 Spyder 进行科学计算和可视化#
本次研讨会将引导您探索 Spyder 的一些功能,这些功能使 Spyder 成为使用 Python 提供的科学工具的理想 IDE。在整个研讨会中,我们将应用科学方法来回答一些与我们的偏好和认知能力相关的问题。本次研讨会结束时,参与者将能够使用 Spyder 探索数据,使用一些统计工具对其进行分析,并绘制变量之间的关系。
先决条件#
您需要安装 Spyder。请访问我们的安装指南以获取更多信息。
重要
Spyder 现在为 Windows 和 macOS 提供了独立安装程序,让您无需下载 Anaconda 或在现有环境中手动安装即可更轻松地启动和运行应用程序。虽然我们仍然支持 Anaconda,但我们建议在这些平台上使用此安装方法,以避免大多数包冲突和其他问题。
此外,最好具备以下先验知识
学习目标#
完成本次研讨会后,您应该能够
应用科学方法回答与心理测量变量相关的问题
了解如何使用 Spyder 内置的科学计算工具
学习者画像#
本次研讨会面向希望学习如何从数据集中科学地回答问题的人。我们还将其设计为学习如何将 Spyder 用作研究工具的教程。
介绍#
本次研讨会将探索一个数据集,并使用科学方法回答一些问题。
为什么用 Python 进行科学研究?#
Python 是一种成熟的编程语言,已被科学界广泛选择用于支持研究过程。原因有以下几点:
它功能多样,易于学习和使用
它支持多种方式处理输入和输出。无论您的数据格式如何,Python 中总有一种方法可以导入它(并以您选择的格式导出)
它是一种解释型语言。您无需从头到尾编写代码即可查看部分结果。这使得探索数据变得特别容易和快速
它是机器学习最广泛使用的编程语言(包括 Keras 和 TensorFlow)
它拥有出色的绘图库
它可以与Jupyter Notebooks及其在云端的实现(Google Colab 或 Binder)集成
Spyder 如何帮助我的科学研究?#
Spyder 是一个用 Python 编写的科学集成开发环境,由科学家、工程师和数据分析师设计。它独特地结合了综合开发工具的高级编辑、分析、调试和性能分析功能,以及科学软件包的数据探索、交互式执行、深度检查和精美可视化功能。结合 Python,它提供了一套非常完整的科学计算工具。
科学方法的基本步骤#
科学方法是一套用于以有效方式获取新知识的良好实践。广义地说,科学方法的阶段如下:
观察:首先找到需要解释的事物
搜索/生成理论:就世界的现状或其运作方式发表一两点看法(关于现象的抽象思考)
假设:识别变量并进行预测
测试/实验/更多观察:测量变量之间的关系
分析:拟合模型/绘制数据图
报告:分享新发现
在整个研讨会中,我们将以实用方式开发这些步骤。我们将使用 Spyder 作为研究工具,并使用来自在线约会网站的心理测量数据,使其变得轻松有趣。
Spyder 科学研究入门#
如果您不熟悉 Spyder,建议您从我们的快速入门开始。但如果您想了解摘要,这里有一个快速概述。
注意
如果您已经有 Spyder 使用经验,可以跳到准备工作部分。
编辑器#
编辑器是您编写代码并将其保存为文件(脚本)的地方。它允许您轻松地保留您的工作。在这里,您可以编写希望保留在 IPython 控制台中进行数据分析的代码。您还可以在这里阅读、编辑和运行本次研讨会的代码。
IPython 控制台#
IPython 控制台是 Spyder 的组件,您可以在其中编写要进行实验的代码块。在本次研讨会中,我们将为您提供可以在此控制台中复制和运行的代码片段。
本质上,IPython 控制台允许您使用 Python 执行命令并与数据交互。
变量探索器#
变量浏览器是 Spyder 最好的功能之一。它允许您交互式地浏览和管理当前选定的IPython 控制台会话中生成的对象。
变量浏览器是本次研讨会中最常用的组件之一。这是我们将观察数据和大部分科学分析结果(除了图表)的窗格。
绘图窗格#
绘图窗格显示了 IPython 控制台会话中创建的所有静态图表和图像。代码生成的所有绘图都将出现在此组件中。您还可以将每个图形保存到本地文件或复制到剪贴板,以便与其他研究人员共享。
准备工作#
开始之前,您必须安装一些运行代码所需的包和库。我们建议您在虚拟环境中安装这些要求。这里我们逐步解释如何操作。
设置 Conda 环境#
如果您希望将 Spyder 放在一个专用环境中,以便与您的其他包分开更新并避免任何冲突,您可以这样做。
您可以通过两种不同的方式设置环境。
重要
我们建议使用Anaconda(或Miniconda)创建虚拟环境,因为它与 Spyder 无缝集成。您可以在Anaconda 文档中找到安装说明。
1. 使用命令#
只需在 Anaconda Prompt (Windows) 或终端(其他平台)中运行以下命令,即可将 Spyder 最小安装到名为scientific-computing的新环境中
$ conda create -n scientific-computing
要同时安装 Spyder 的可选依赖项以获得完整功能,请改用以下命令
$ conda create -n scientific-computing spyder=5 numpy scipy pandas matplotlib sympy cython seaborn spyder-kernels pyarrow
警告
Spyder 现在为 Windows 和 macOS 提供了独立安装程序,让您无需下载 Anaconda 或在现有环境中手动安装即可更轻松地启动和运行应用程序。如果您使用独立安装程序,则无需使用 conda 安装spyder=5。
2. 从 environment.yml 文件#
您还可以使用我们与您共享的环境文件(scientific-computing.yml)轻松安装虚拟环境。只需在终端中运行以下命令(您必须在当前目录中拥有环境文件)
$ conda env create -f scientific-computing.yml
激活环境#
您现在可以这样进入新创建的虚拟环境
$ conda activate scientific-computing
下载数据集#
我们将使用一个名为 OKCupid 的公共数据集,由 Kirkegaard 和 Bjerrekaer 收集。该数据集由 68,371 条记录和 2,626 个变量组成。
将OKCupid 数据集下载到您选择的目录中。
设置工作目录#
虚拟环境和数据文件现已准备就绪。唯一剩下要做的就是创建一个工作目录。在您的操作系统中,创建一个您选择的新目录。然后将数据集文件复制并解压到那里。
这是一个示例(在 Linux 或 macOS 上)
$ mkdir scientific-computing
$ cd scientific-computing
请记住,在此新目录中,您必须解压缩数据文件。
启动 Spyder
$ spyder
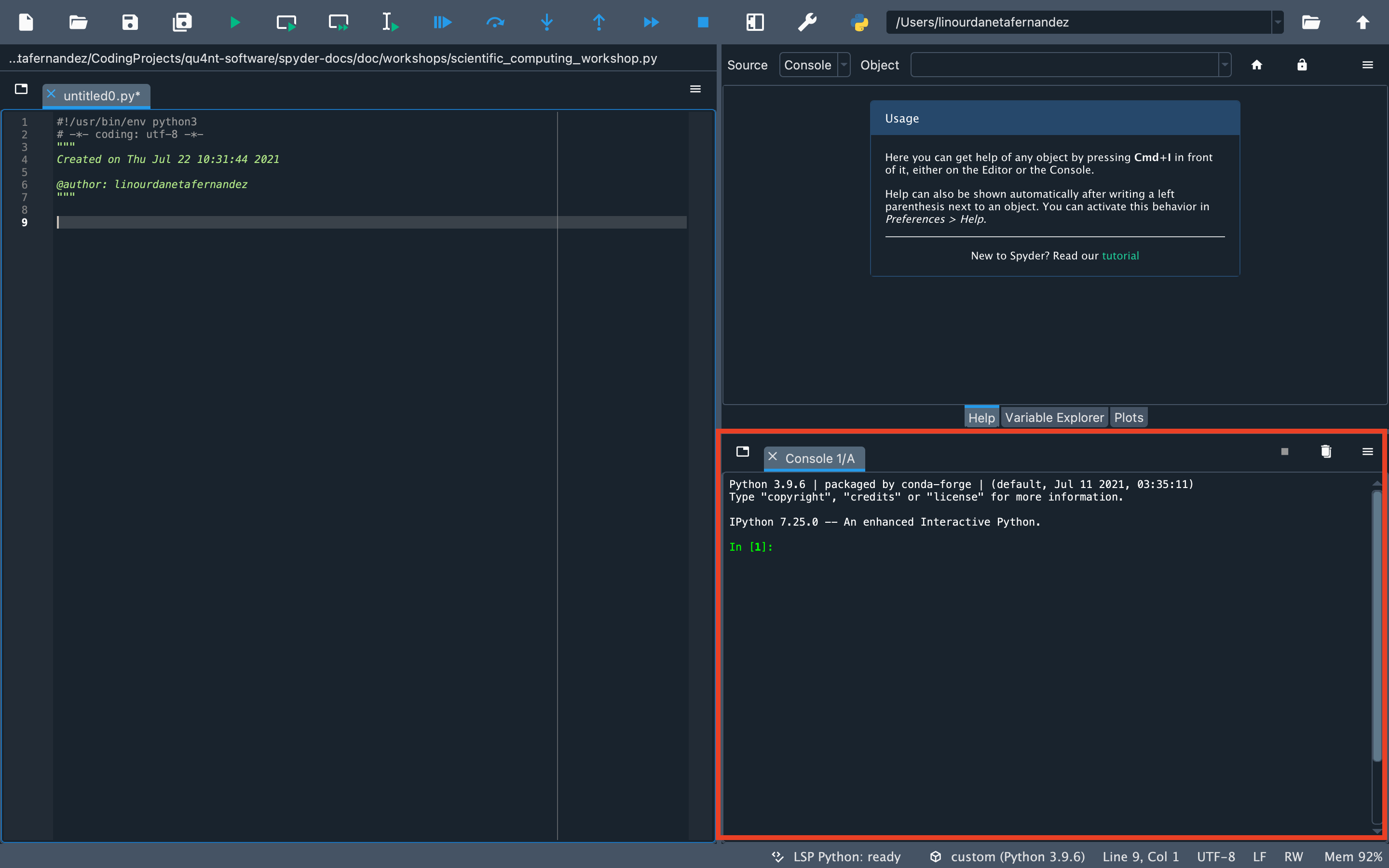
让我们确保 Spyder 已准备就绪。首先,检查工作目录是否正确。您应该在右上角看到数据集所在目录的路径。类似这样:

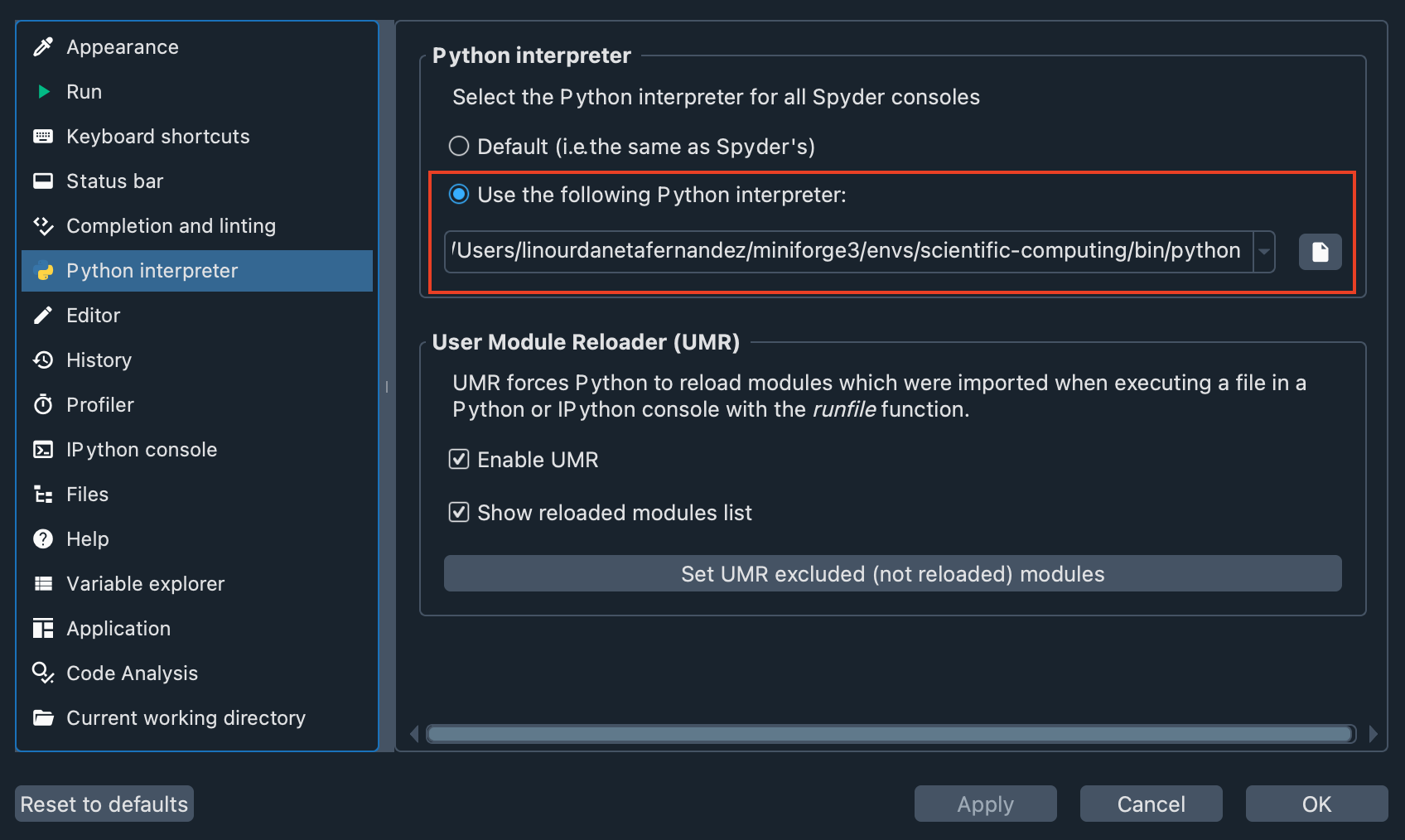
其次,让我们检查我们创建的虚拟环境是否在 Spyder 中启用。转到首选项 > Python 解释器,然后使用使用以下 Python 解释器下的下拉菜单选择您的虚拟环境路径。您应该会看到类似这样的内容:
现在,您已准备好继续进行研讨会。
下载代码#
尽管本次研讨会旨在让您在 IPython 控制台中编写代码,但我们创建了一个文件供您下载。此脚本提供了您将在本次研讨会中编写的所有代码,如果您迷路了,可以将其用作指南。
数据集#
OKCupid 是一个收集自在线约会网站 OKCupid 的信息数据集。它由 68,371 条记录组成,这些记录是通过抓取器自动提取公共信息而收集的。
数据集包含人口统计数据(例如,性别、性取向和年龄)。它还包括网站算法用于计算某些人格指标以帮助找到兼容匹配的一般问题的答案。
如果您想了解有关此数据集如何收集以及包含何种信息的更多信息,可以在此论文中获取:The OKCupid dataset。
请记住在 Spyder 右下角的“IPython Console”中键入并运行本次研讨会的所有代码。
您也可以在编辑器(占据 Spyder 整个左侧的窗格)中编写代码。如果您使用编辑器,可以通过选择代码并点击运行工具栏中的运行选定内容或当前行按钮或按 F9 键来运行代码。
首先,导入库。
import matplotlib.pyplot as plt
import pandas as pd
import scipy.stats as stats
import seaborn as sns
您之前下载的数据采用parquet格式。这种格式非常方便,因为它比 CSV 或 JSON 文件更小、更快。
加载数据
data = pd.read_parquet("parsed_data_public.parquet")
您现在应该能够在变量浏览器中看到您导入的数据。
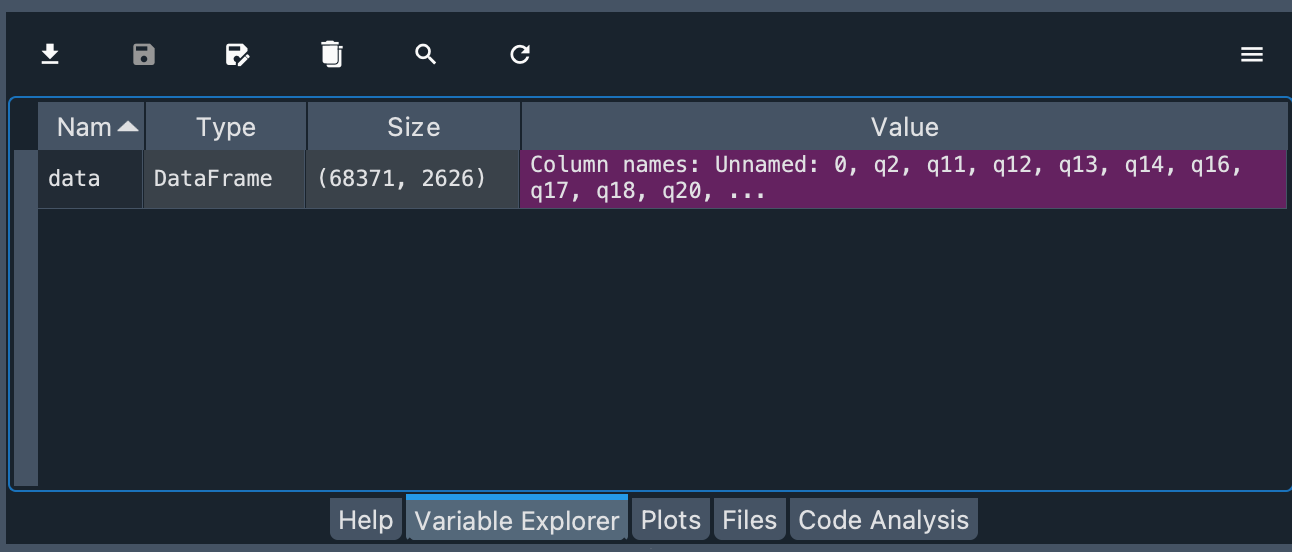
您可以看到对象类型为 DataFrame,以及对象的行数和列数。
探索数据集#
年龄#
现在,让我们探索其中一个变量,在本例中是数值变量年龄(d_age)。
注意
在 OKCupid 数据集中,所有人口统计变量都以“d_”为前缀,而个人资料变量则以“p_”为前缀。
data.d_age.describe()
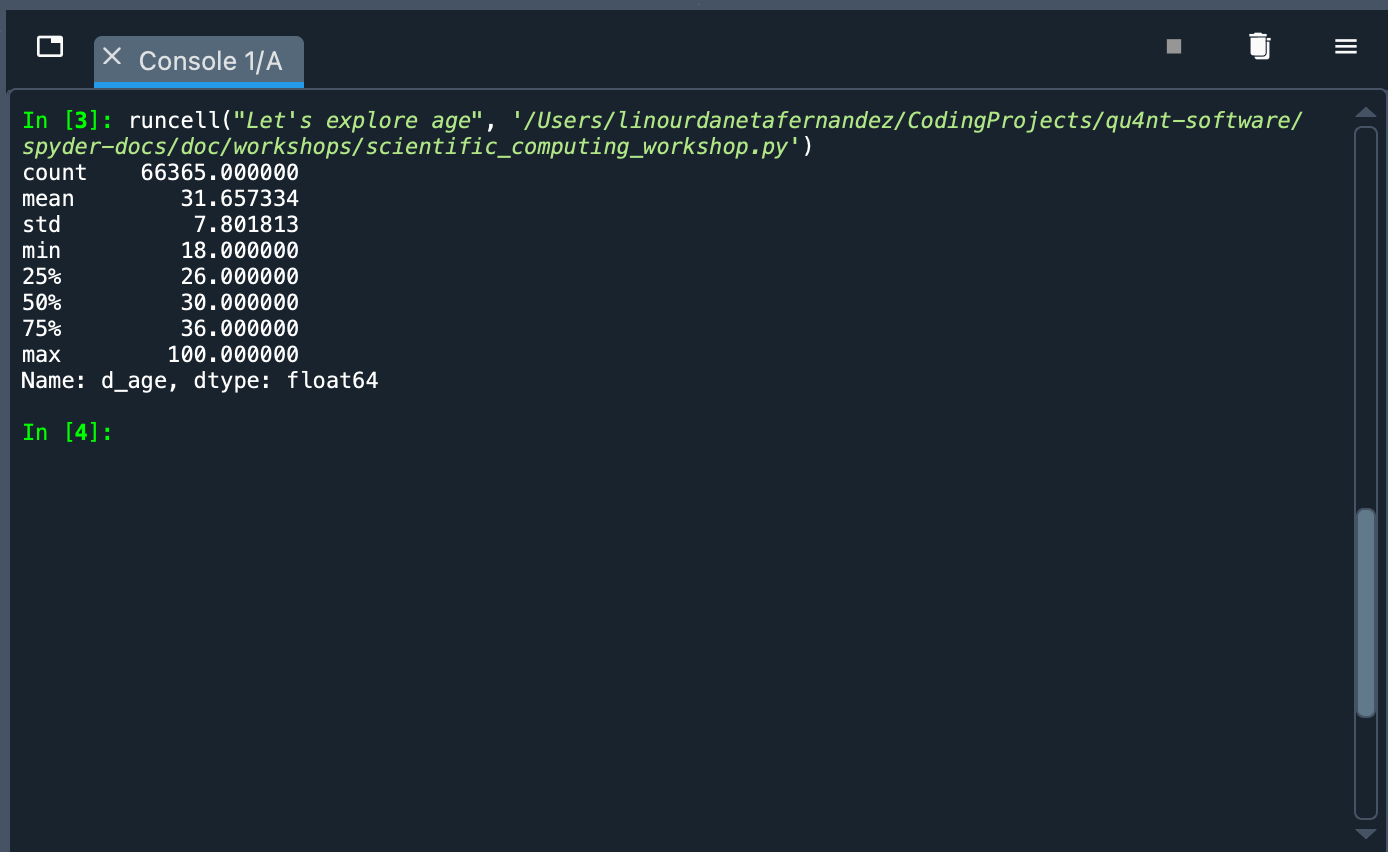
发生了什么?我们调用了data对象,并使用 Python 的点表示法选择d_age列。这有一个Pandas Series类型对象。我们向该对象传递了describe()方法,该方法显示了一些指标的摘要:值计数、均值、标准差、最大值、最小值等。从这些数据中我们可以看到,样本主要由年轻人组成(平均年龄为 31.65 岁)。
函数、方法或对象的属性的返回值可以作为变量存储,以便在变量浏览器中随时可用。
max_age = data.d_age.min()
min_age = data.d_age.max()
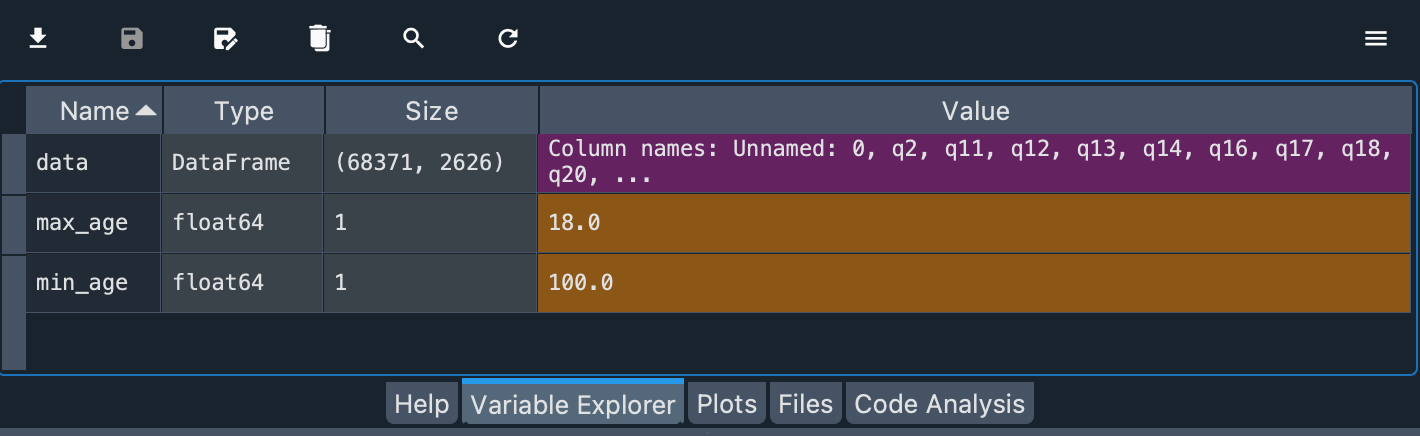
这些值是浮点数。最低年龄是 18.0 岁,最高年龄是 100.0 岁。
注意
还要注意,每种类型的变量都有不同的颜色,以便快速区分它们。
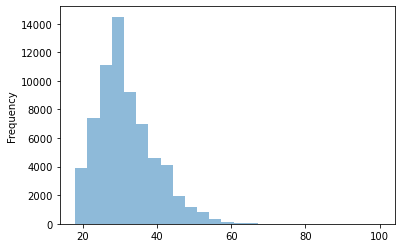
我们已经知道最小和最大年龄,并且平均年龄约为 32 岁。进一步探索这个变量的好方法是绘制直方图,这是一种显示频率分布的图表。通过这种方式,我们可以看到平台上年轻群体的数量是否多于老年群体。
我们可以直接从数据框绘制直方图。为此,我们选择变量(如我们使用.describe()所做的那样),并调用.plot.hist()方法。在此方法中,我们将传递 bin 的数量和绘图的透明度(alpha)作为参数。
data.d_age.plot.hist(bins=25, alpha=0.5)
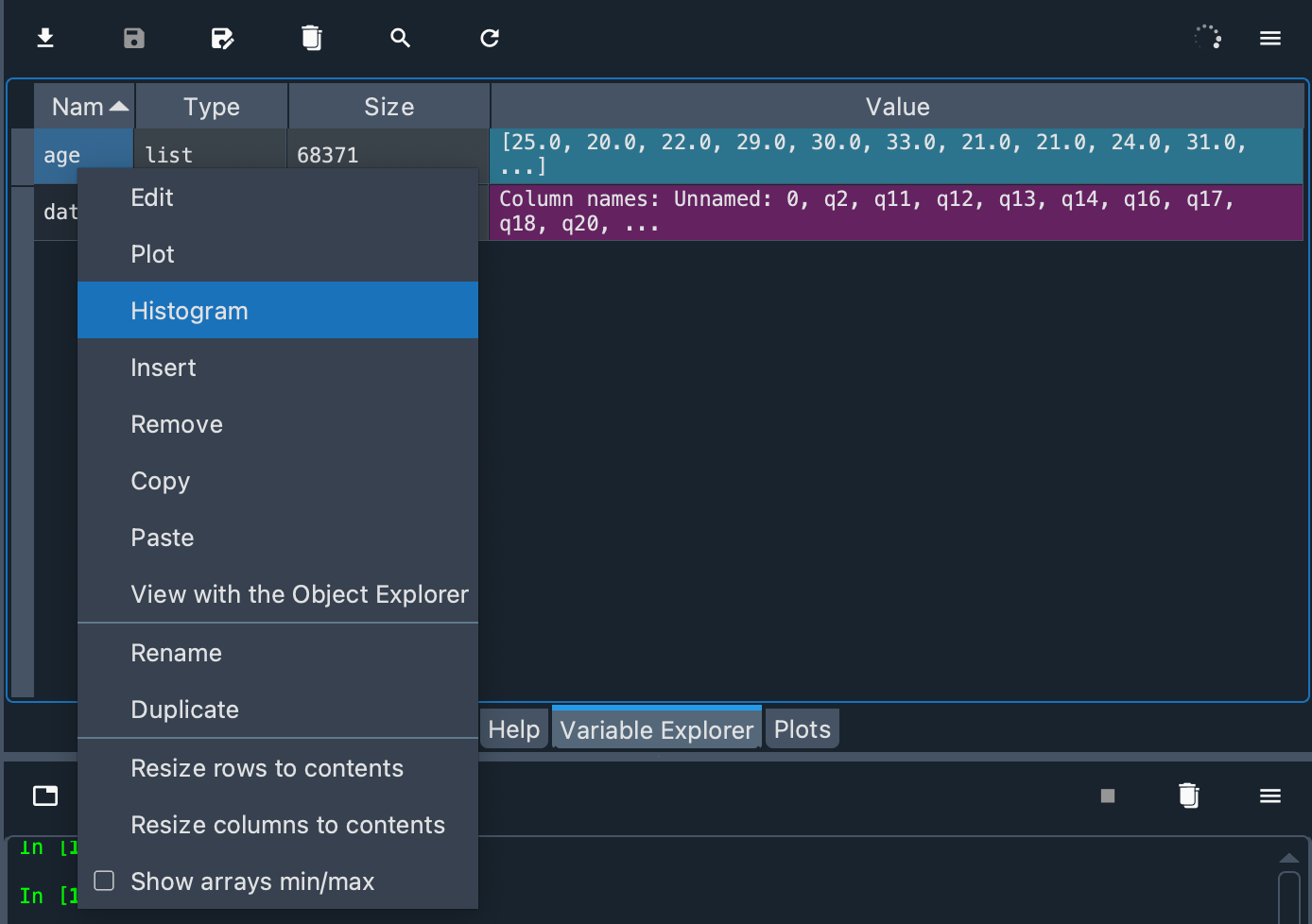
在 Spyder 中生成简单直方图的另一种方法是使用变量浏览器中数组的上下文菜单。但首先我们必须将这些值存储在一个列表中,并将该变量命名为age。
age = data.d_age.tolist()
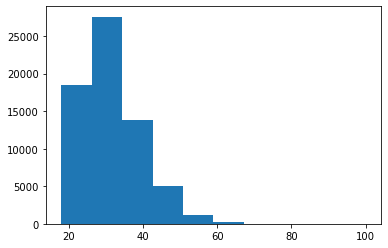
频率分布有不同的尺寸和形状。直方图的形状揭示了关于数据的一些非常有趣的信息。对称的钟形直方图可能表明分布是正态的(大多数分数接近分布的中心)。在年龄直方图中,您可以看到它右侧(朝向老年)有一个“尾巴”。这在技术上被称为“正偏斜”。还可以注意到它有点尖(正峰度或尖峰)。这两点可能表明年龄不是一个随机变量。
虽然我们可以直接从数据框创建直方图,但我们将使用一个名为 Seaborn 的 Python 库来做同样的事情,因为这个库以后会让我们做更有趣的事情。
sns.histplot(data.d_age, kde=True, bins=25)
plt.show()
我们调用sns.histplot()并带有三个参数。第一个参数(data.d_age)是一个 Pandas Series,其中包含我们想要绘制的定量变量。第二个参数(kde=True)添加了一条曲线,显示年龄分布的理想模型(使用一种称为核密度估计器的方法)。第三个参数(bins=25)表示我们希望图中有 25 个 bin。
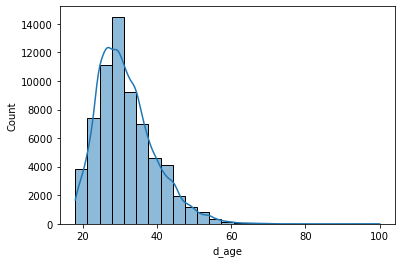
第二行(plt.show())旨在显示所有尚未显示的图形。如果您对如何使用对象、方法或函数有任何疑问,可以使用控制台中的help()工具。例如:
help(plt.show)
或者您也可以利用 Spyder 中包含的帮助窗格获取屏幕帮助。
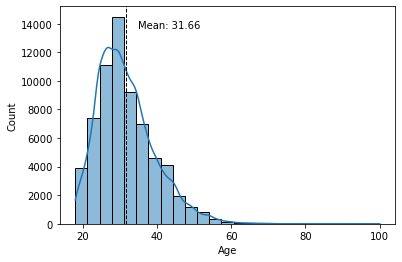
使用 Seaborn,我们可以添加一条代表直方图均值的线。为此,我们将使用axvline()方法,并添加一个带有均值值的文本,其中text()、min_ylim和max_ylim用于标记文本的位置。
sns.histplot(data.d_age, kde=True, bins=25)
plt.xlabel('Age')
plt.axvline(data.d_age.mean(), color='k', linestyle='dashed', linewidth=1)
min_ylim, max_ylim = plt.ylim()
plt.text(data.d_age.mean()*1.1, max_ylim*0.9,
'Mean: {:.2f}'.format(data.d_age.mean()))
plt.show()
宗教信仰认真程度#
我们了解数据框的范围,并且已经了解了如何探索定量变量。现在让我们转到定性变量。columns属性显示数据框中的列名列表。我们还知道人口统计变量以“d_”为前缀,因此我们可以查找与此前缀对应的变量名。
demograph = [v for v in list(data.columns) if v.startswith("d_")]
在变量浏览器中,您将看到一个新变量demograph。如果双击它,您将看到数据集中人口统计变量的列表。在列表末尾,您将看到一个值d_religion_seriosity。如果右键单击它,屏幕上将出现几个选项。您可以重命名列、删除它或插入新列。让我们单击复制将列名复制到内存中。
在 IPython 控制台中,键入data.,然后复制列名。在末尾键入一个句点(无空格),然后按 Tab 键。您应该会看到类似以下内容:
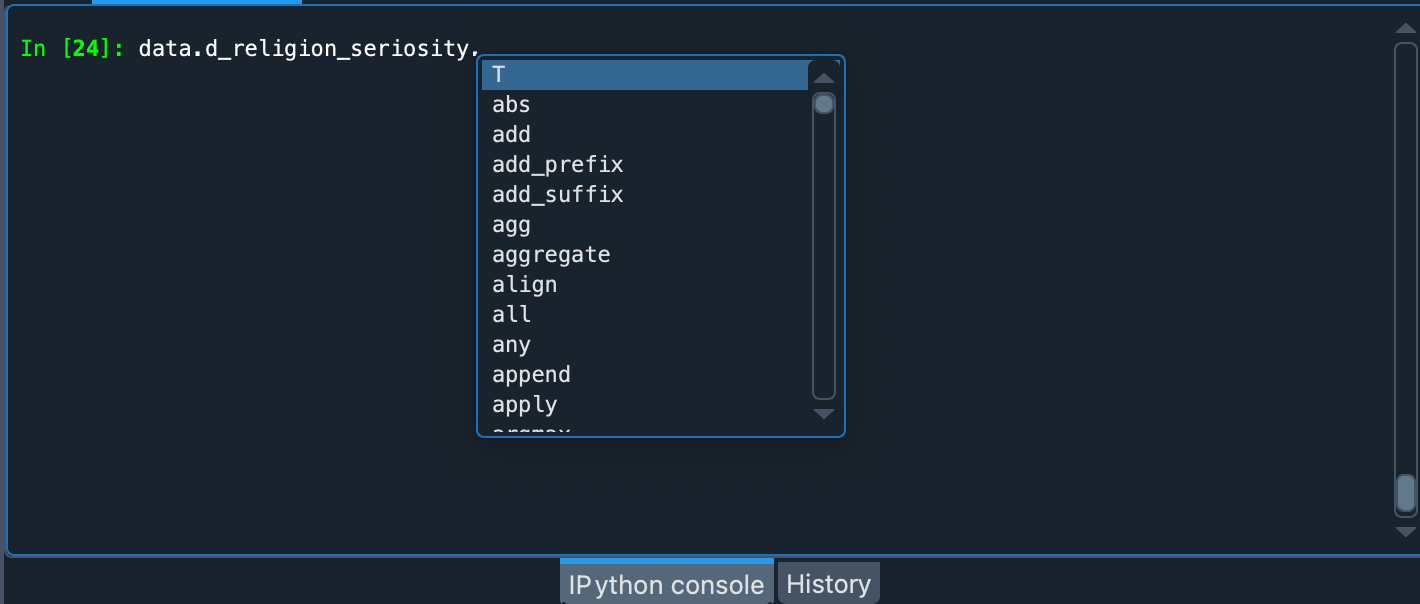
然后,您可以看到该类的所有相关方法和属性的列表。最后您会看到value_counts,可用于汇总变量。它是一个方法,因此必须以括号结尾。
data.d_religion_seriosity.value_counts()
# but not too serious about it 11142
# and laughing about it 7307
# and somewhat serious about it 5372
# and very serious about it 3290
# Name: d_religion_seriosity, dtype: int64
除了人口统计和个人资料变量之外,数据集还包含各种主题问题的答案。这些问题用前缀“q”后跟一个整数编码。问题文本存储在一个名为question_data.csv的文件中(您可以将其作为OKCupid 数据集的一部分下载)。
我们可以在变量浏览器中检查这个文件
question_data = pd.read_csv("question_data.csv", sep=";")
双击变量浏览器中的“question_data”,将每个问题与其代码(“q”+数字)对齐显示。
现在我们已经学会了如何探索数据,我们可以提出有趣的问题,并尝试在数据集和 Spyder 的帮助下回答它们。
构思理论并提出假设#
理论不过是对事物的解释。例如,我们可能会卷入猫狗之间的永恒冲突。我作为一个爱狗人士,可能有一个理论(当然是不科学的),认为那些喜欢狗陪伴的人比那些喜欢一只邪恶(但可爱)的小猫的人更聪明。为了检验理论的支撑,可以根据它做出预测,并观察这个预测在实验或具体情况中的表现。我们称这种预测为假设。
假设是可以通过科学方法检验的陈述。它们必须能够使用经验证据或数据进行验证。例如,绿色是最好的颜色不是一个假设,因为它无法被证明或证伪。
关于上述关于个人宠物偏好的理论,为了探索它,我们应该找到两个变量来关联。第一个变量将与自认为是猫派或狗派有关。第二个变量将与个人解决问题和处理情况的能力有关。
OKCupid 数据集中有一些有用的变量,我们可以用它们来研究这个理论。例如,问题q997(你是猫派还是狗派?)提供了有关个人宠物偏好的信息。第二个变量稍微难以想出,因为它有点复杂。幸运的是,收集数据集的研究人员还选择了 14 个问题,可以作为认知能力测试的替代指标。这些选定的问题可以在OKCupid 数据集中的test_items.csv文件中找到。
test_items = pd.read_csv("test_items.csv")
那么,让我们尝试看看 OKCupid 数据集中是否有任何证据支持以下假设:
喜欢狗而不是猫的人在认知能力测试中得分更高.
注意
剧透警告:如果你是猫奴,并且觉得应该立即离开这个工作坊,我建议你留下来。如果你不是猫奴,也留下来。
构建测试#
我们已经知道哪些问题将作为认知能力测试的一部分。现在我们将处理这些数据以获得每个人的分数。
首先,我们复制原始数据集
ca_test = data.copy()
然后,我们找到每个测试问题的正确答案(这些答案在test_items中)。
right_answers = []
for ID, ROW in test_items.iterrows():
right_answers.append(ROW.iloc[ROW["option_correct"] + 2])
test_items["right_answer"] = right_answers
正确答案已存储在test_items数据框中。
接下来,我们将在ca_test数据框中指示此人是否正确回答了认知能力测试中选择的每个问题。这些答案将以布尔值的形式输入到以“resp_”为前缀的新变量中,后跟相应的问题代码。布尔值使用函数lambda row: row[q] == a, axis=1计算。
for ID, ROW in test_items.iterrows():
QUESTION = "q" + str(ROW["ID"])
ANSWER = str(ROW["right_answer"])
try:
ca_test.dropna(subset=[QUESTION], inplace=True)
ca_test["resp_" + QUESTION] = ca_test.apply(lambda row: row[QUESTION] == ANSWER, axis=1)
except KeyError:
print(f"{QUESTION} not found.")
重要
一些test_items问题不在数据中,但请不要担心。我们使用try... except块来忽略这些错误。回答这些问题是可选的,因此许多 OkCupid 网站用户没有回答所有问题。因此,我们从记录中删除了未回答我们为认知能力测试选择的 14 个问题的用户。这大大减少了样本量。还有其他方法可以避免这种减少,但这超出了本次研讨会的范围。
我们想计算每个人的正确答案总和,但一些整数结果被存储为字符串,所以让我们修正一下。
ca_test.q18154 = pd.Series(ca_test.q18154, dtype="int")
ca_test.q18154 = pd.Series(ca_test.q18154, dtype="string")
ca_test.resp_q18154 = ca_test.apply(lambda row: row["q18154"] == "26", axis=1)
ca_test.q255 = pd.Series(ca_test.q255, dtype="int")
ca_test.q255 = pd.Series(ca_test.q255, dtype="string")
ca_test.resp_q255 = ca_test.apply(lambda row: row["q255"] == "89547", axis=1)
现在我们已经有了每个测试问题的正确答案,让我们将每个人的正确答案加起来。有 14 个问题,所以最高分也将是 14 分。
cognitive_score = ca_test[list(ca_test.filter(regex="^resp"))].sum(axis=1)
ca_test["cognitive_score"] = cognitive_score
我们如何汇总这些响应?请记住,每个答案都以布尔值(True 或 False)形式存储,并带有“resp_”前缀。因此,我们在ca_test数据框中搜索以“resp”开头的每列的答案(我们使用正则表达式regex="^resp"和filter方法),并使用sum(axis=1)计算每行的 True 值之和。然后,我们将这些结果存储在ca_test数据集的“cognitive_score”列中。
您可以通过在 IPython 控制台中键入ca_test.cognitive_score.describe()来查看这些操作的结果。如果您这样做,在count中您将看到新记录的数量已减少到 479(其余 68,371 名用户未回答所有这些问题)。
认知能力分布#
让我们绘制这个变量的直方图,以查看频率分布。
sns.histplot(ca_test.cognitive_score, kde=True, bins=6)
sns.set_palette(palette)
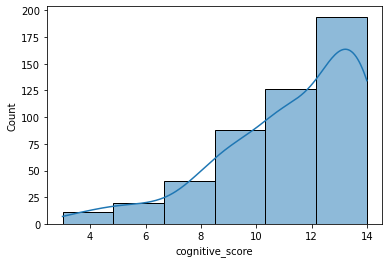
如您所见,在这种情况下,分布不对称,但在左侧有一个长长的“尾巴”(负偏)。这意味着大多数回答了所有问题的用户表现都很好,只有少数用户回答了大多数问题,但方式错误。
重要
我们在这部分计算的值已经存在于数据中(data.CA_items)。然而,我们选择使用代码再次获取这些结果,因为这是学习如何使用 Python 和 Pandas 提供的工具进行数据操作的好方法。
关联变量#
请记住,假设关联了两个变量:您更喜欢哪种宠物和认知能力。宠物偏好的测量将来自问题q997(分类或定性变量),认知能力将从测试中正确答案的总和中测量(定量区间变量)。使用这种类型的变量,我们可以制作一些箱线图,看看均值之间是否存在差异。
但首先,让我们更改标准的 Seaborn 调色板,以获得更漂亮的图表。
palette = sns.color_palette("husl")
sns.palplot(palette)
注意
Seaborn 允许您选择不同的图形样式和颜色调色板。更多信息请访问https://seaborn.org.cn/tutorial/color_palettes.html
现在,我们将创建箱线图来观察变量之间的关系。为此,我们将使用 Seaborn 的catplot类。第一个参数是 x 轴,在本例中是定性变量(问题q997)。第二个参数是 y 轴,我们将放置定量变量(认知分数)。通过参数kind我们指示它是一个箱线图。参数height和aspect调节图的外观。最后一个参数data指示数据来源。
sns.catplot(x=ca_test.q997, y=ca_test.cognitive_score,
kind="box", height=5, aspect=2, data=ca_test).set_axis_labels("q997 = Are you a cat person or a dog person?", "cognitive score")
sns.set_palette(palette)
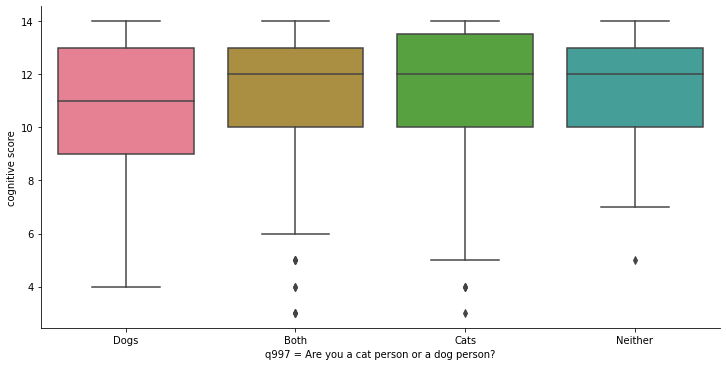
箱线图或盒须图在箱体的中心附近以水平线显示数据的均值。箱体边缘的线代表50%的观测值(四分位距)。在箱体外部,向上和向下,我们发现两个须:下须代表数据集中下部值的均值,上须代表数据集中上部值的均值。超出须的点是异常值。
重要
异常值是与其余数据值非常不同的值。它们必须予以考虑,因为它们经常会在我们尝试拟合数据的模型中产生偏差。
该图表显示了以下组的认知能力测量结果的四个箱体:
喜欢狗的人
不分猫狗,都自称猫派和狗派的人。
喜欢猫的人
不喜欢猫也不喜欢狗的人。
最低平均值是那些只喜欢狗的人,但差距很小。代表爱狗人士的箱体(和边界)也“更宽”,这意味着该组个体测试结果的变异性更大。但这与喜欢猫的人的离散程度相差不大。所有平均值都在其他箱体(四分位数)的范围内,这似乎表明,事实上,这些组在智力测试分数上并没有真正重要的差异。这似乎削弱了我们上面提出的初始假设的支持。
注意
如果您想查看具体数值,请在 IPython 控制台中输入dog_or_cat = ca_test.groupby("q997")["cognitive_score"].describe(),然后在变量浏览器中查看结果。这样您就可以看到有多少人喜欢猫或狗,以及每个组认知能力测试结果的均值和标准差。
为了在上下文中了解平均值的真实差异,让我们创建一些条形图。我们现在将使用 Seaborn 的条形图类。在 x 轴上,我们再次放置定性变量(q997),在 y 轴上放置定量变量(cognitive_score)。数据参数将整个数据集作为参数。
fig_dims = (12, 8)
fig, ax = plt.subplots(figsize=fig_dims)
sns.barplot(x=ca_test.q997, y=ca_test.cognitive_score, ax=ax, data=ca_test)
sns.set_palette(palette)
plt.xlabel("q997 = Are you a cat person or a dog person?")
plt.ylabel("cognitive score")
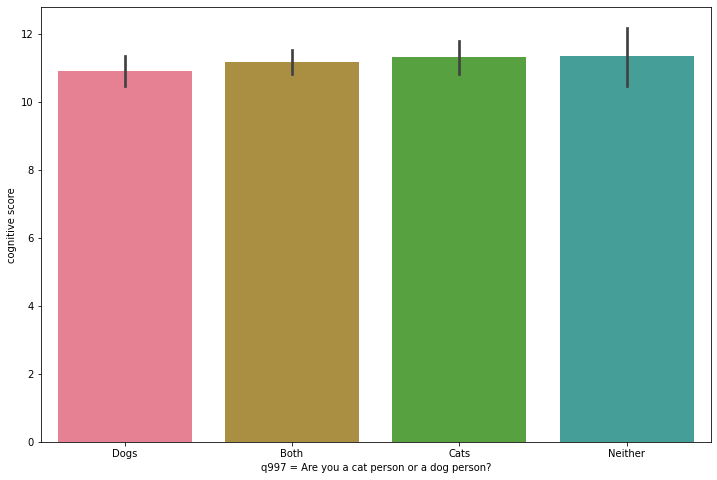
如果箱线图表明均值没有显示出显著差异(可能是偶然的),那么条形图证实这些差异按比例而言是相当微不足道的。
方差分析 (ANOVA) 测试#
为了确保均值之间的差异具有统计学意义,我们将执行方差分析 (ANOVA),因为我们将比较两个以上组的均值。
方差分析是如何工作的?这种分析告诉我们三个或更多均值是否相等。如果相等,这将支持零假设。
注意
零假设是对我们假设中陈述的另一种预测。零假设简单地指出观察到的均值差异是由于样本收集时发生的随机变异造成的。
ANOVA 产生一个F 比率(也称为 F 统计量),它将数据中系统变异量(可以由模型或假设解释的变异)与非系统变异量(不能由我们的假设或模型解释的变异)进行比较。这意味着 F 是模型与其误差的比率。ANOVA 还产生一个p 值,表示变异可能归因于零假设的概率。p 值越小,观察到的变异是由于偶然造成的可能性越小。
格式化数据#
为了执行方差分析,让我们首先通过对认知能力测试结果数据集进行透视。宠物偏好值现在将成为列名,每行将代表一个人。
警告
要执行方差分析,必须满足某些要求或假设。例如,残差的分布必须是正态的。这里不是这种情况。对于本示例,有更合适的统计测试,并且在这种情况下有可能对数据进行某些转换以应用方差分析。但是,我们使用方差分析是因为它是一个相当流行的测试,并且本次研讨会的目的是作为 Spyder 科学计算的介绍。我们不打算在这里获得可发表的科学结果。
dog_or_cat_pivot = ca_test.pivot(columns="q997", values="cognitive_score")
您会看到其中一列包含未指定宠物偏好的人所做的测试的答案。让我们删除那一列。
dog_or_cat_pivot.drop(dog_or_cat_pivot.columns[0], axis=1, inplace=True)
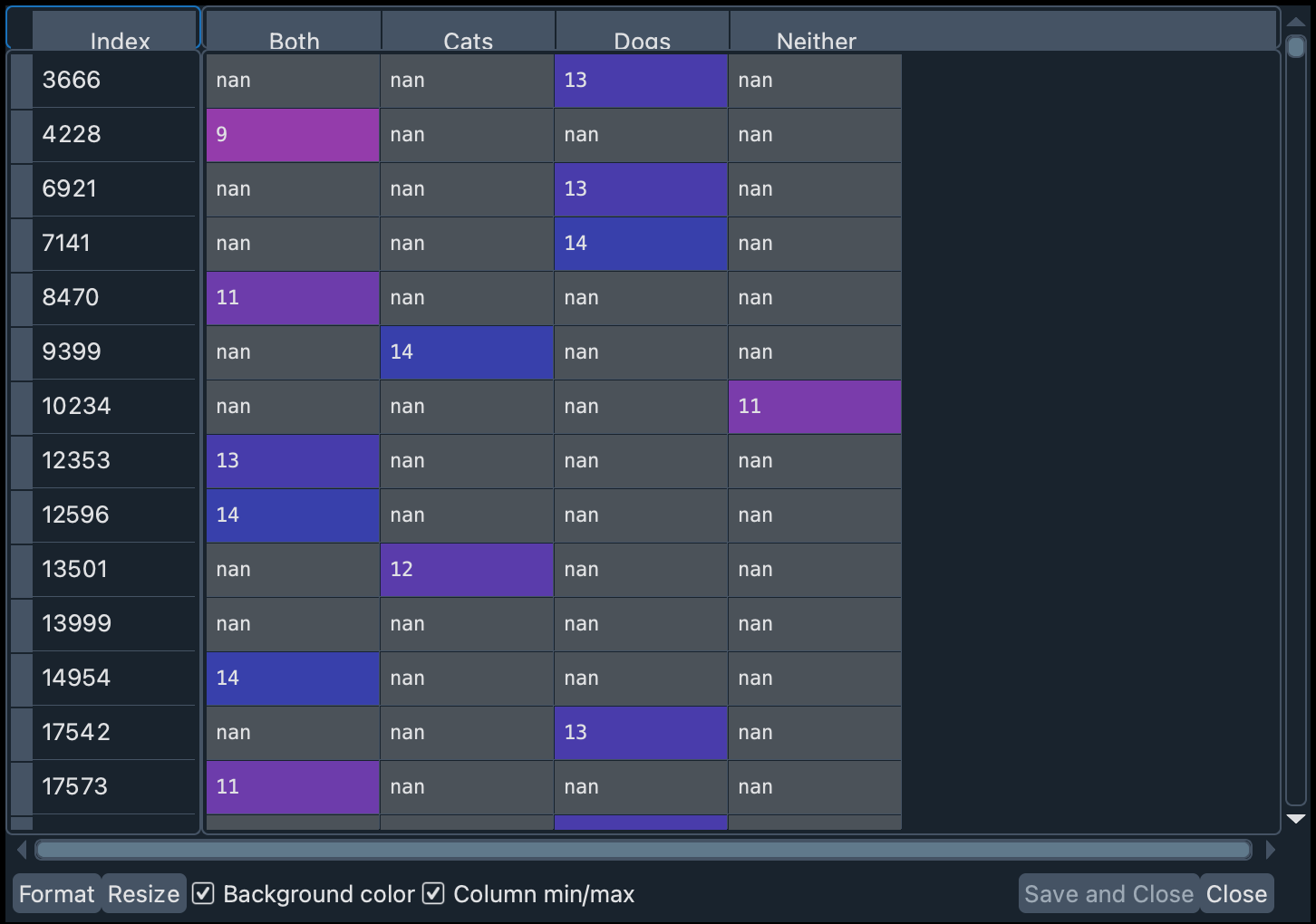
现在让我们重命名列名(为简单起见)并删除具有缺失值的记录(使用dropna)。参数inplace=True允许您直接修改数据框,而无需创建新的数据框。
dog_or_cat_col_names = list(dog_or_cat_pivot.columns)
dog_or_cat_pivot.columns = ["A", "B", "C", "D"]
dog_or_cat_pivot.dropna(how="all", inplace=True)
注意
在变量dog_or_cat_col_names中,我们按顺序存储了值的名称。这意味着:A = 两者,B = 猫,C = 狗,D = 两者都不是。
为了执行方差分析,我们将使用一个名为“stats”的 Python 库,特别是f_oneway函数。您可以通过在帮助窗格中键入stats来找到有关此库的更多信息,或者通过键入stats.f_oneway来了解有关该函数的更多信息。
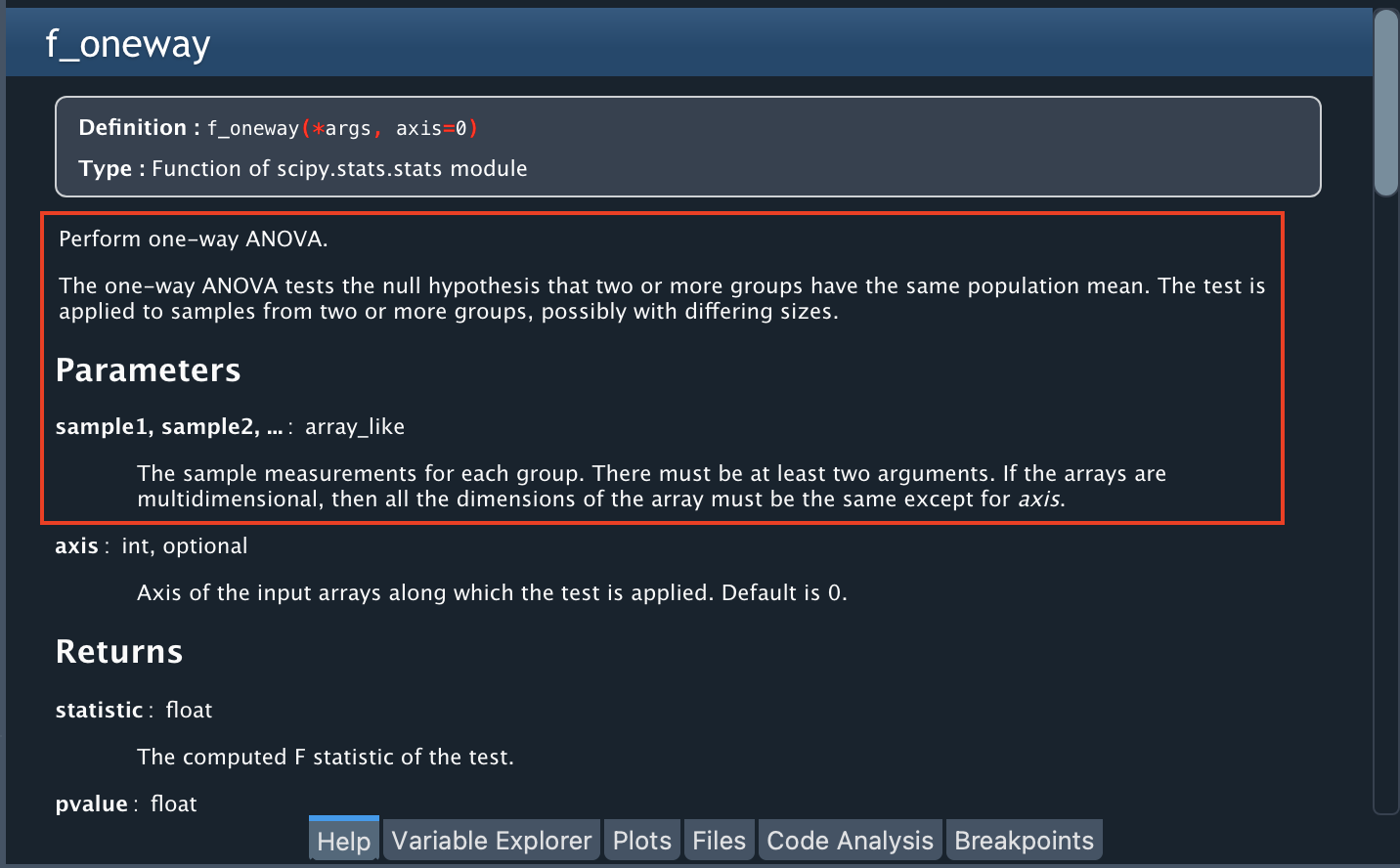
帮助说明此函数需要一个类数组作为输入,其中包含每个组的测量值(在我们的例子中,A、B、C 和 D 各一个样本)。由于每列都有空单元格,让我们将它们从每列中删除(f_oneway函数不支持缺失值)。
dog_or_cat_samples = [dog_or_cat_pivot[col].dropna() for col in dog_or_cat_pivot]
在上面的代码行中,我们创建了一个包含 4 个元素的列表:A、B、C 和 D 每列的测试结果,不含缺失值(使用dropna()删除)。
运行方差分析#
现在,让我们运行方差分析并将输出存储在两个变量中:f_value和p_value。请注意,由于dog_or_cat_samples是一个列表,我们必须带星号传递参数(*dog_or_cat_samples)。
f_value, p_value = stats.f_oneway(*dog_or_cat_samples)
在帮助窗格中,您将通过stats.f_oneway阅读此函数输出的描述、有关测试的一些有趣说明以及一些可用于更好地理解此分析性质的参考资料。
重要
在帮助窗格中,您将读到方差分析需要满足某些假设。在本次研讨会中,我们没有检查这些假设,因为我们的目标仅仅是展示一些使研究工作更轻松的 Spyder 函数。因此,本示例中通过方差分析获得的结果不应过于严格地看待。
在变量浏览器中,您可以找到这两个新变量:f_value和p_value。p_value(0.6275)远高于 0.05,这支持了零假设(削弱了对我们假设的支持)。要了解获得的 F 值是否大于理论预期值,必须计算一个F 临界值。这可以使用stats库、显著性水平(q)以及组数和观测数目的自由度(df)来估计。
num_groups = len(dog_or_cat_pivot.columns)
num_observations = len(dog_or_cat_pivot)
dfn = num_groups - 1
dfd = num_observations - num_groups
f_critical = stats.f.ppf(q=0.95, dfn=dfn, dfd=dfd)
f_critical的值(2.6241)大于f_value(0.5813)。这意味着这些组均值之间的方差没有显著差异。由于 p 值表明我们无法排除随机变异,因此我们必须抛弃我们的假设。
这一切的结论是什么?我们的数据似乎很少或根本没有证据表明一个人的宠物偏好与他或她解决实际或抽象问题的能力之间存在相关性。猫狗主人,欢呼吧!
报告与分享#
在科学领域,分享成果,无论是好是坏,都至关重要。如今,在科学计算中,分享数据以及用于处理和分析数据的代码也至关重要。为了帮助实现这一点,我们将使用 Spyder 的代码分析功能。
代码分析#
分享代码时,您希望它易于阅读、整洁且不过于复杂。代码分析组件可以帮助我们检测这些问题,甚至可能影响代码性能的错误。
要查看示例,您可以打开scientific-computing-astro.py文件并运行代码分析(在窗格中打开文件并点击右上角的绿色三角形按钮)。
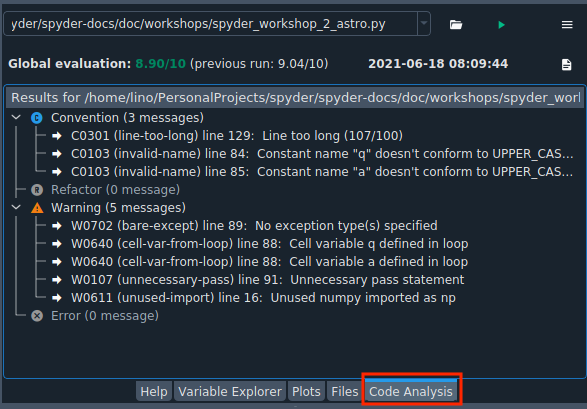
您可以看到四个类别可以帮助您改进代码:
约定:违反编程标准
重构:与重构相关的检查
警告:Python 特有问题
错误:代码中可能存在的错误
这些类别中的每一个都指示了警报的类型以及潜在问题发生的行。例如,它告诉我们第 129 行太长,或者我们导入了 numpy 但在代码中根本没有使用它。
这些建议有助于共享干净的代码。我们建议在发布代码之前使用此面板来完善您的代码。
结束语#
在本次研讨会中,我们迈出了使用 Spyder 进行科学计算的第一步。我们看到了一个问题或疑问是如何提出假设的。这个问题也可以从对一些数据的探索中产生,这可以通过计算一些度量(如均值、中位数、标准差)或绘制一些图表来完成。
通常,为了回答问题,我们必须处理一些数据(例如,用于构建认知能力测试)。
最后,我们尝试通过一些统计测试来建立变量之间的关系。这些测试的结果将支持或不支持我们最初的假设。
在本工作坊中,您已学会如何
设置 Conda 环境。
使用 IPython 控制台和编辑器编写并测试代码。
下载数据集。
在变量浏览器中检查对象。
以图形方式探索数据集。
使用绘图窗格在绘图之间浏览。
探索数据并将其与假设关联起来。
在 Pandas DataFrame 中操作数据。
使用专业库对数据执行统计测试。
通过代码分析提高代码可读性。
Spyder 拥有许多可以帮助您进行数据分析的功能。您可以在我们的官方文档中找到更多信息。
感谢您完成本次研讨会!我们希望它对您有所帮助和启发。
如果您对使用 Spyder 进行金融分析入门感兴趣,可以访问研讨会使用 Spyder 进行金融数据分析。
作业#
如果您想检验所学知识,我们建议您分析数据,尝试回答以下问题:不同的星座是否会影响认知能力测试的结果?如果您有任何疑问,可以查看 Python 脚本scientific-computing-astro.py。
延伸阅读#
有关所用数据集的描述,请参阅以下论文
Kirkegaard, E. O. W., & Bjerrekær, J. D. (2016). The OKCupid dataset: A very large public dataset of dating site users. Open Differential Psychology. doi:10.26775/odp.2016.11.03*
以下是一本学习 R 语言统计学的非常有趣的书:
Field, A., Miles, J., & Field, Z. (2012). Discovering statistics using R. SAGE Publications.